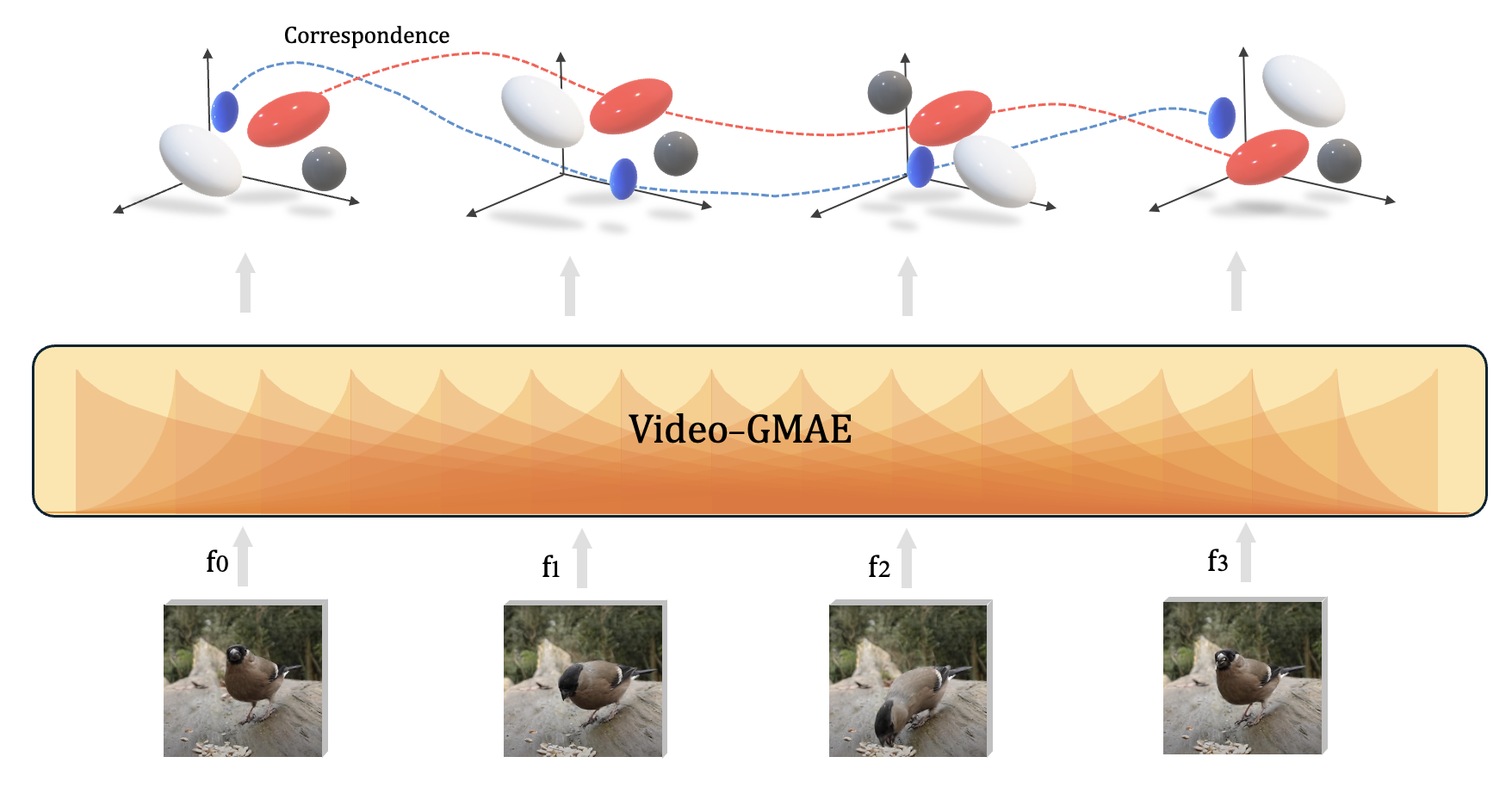
Method
Masked video → ViT encoder → Gaussians for frame 1 + deltas for later frames → differentiable splatting reconstruction.
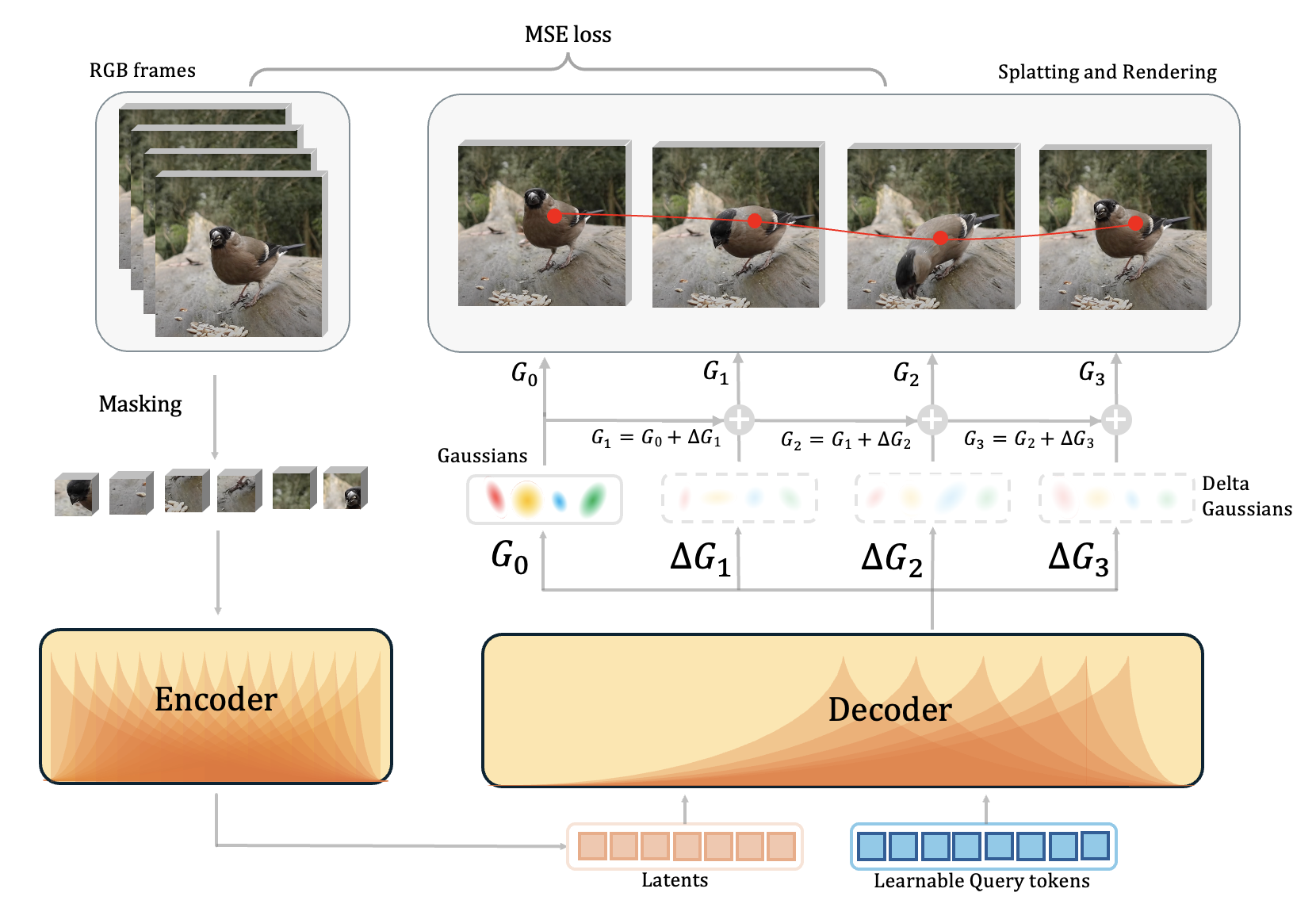 Video masked autoencoding via Gaussian splatting.
Video masked autoencoding via Gaussian splatting.
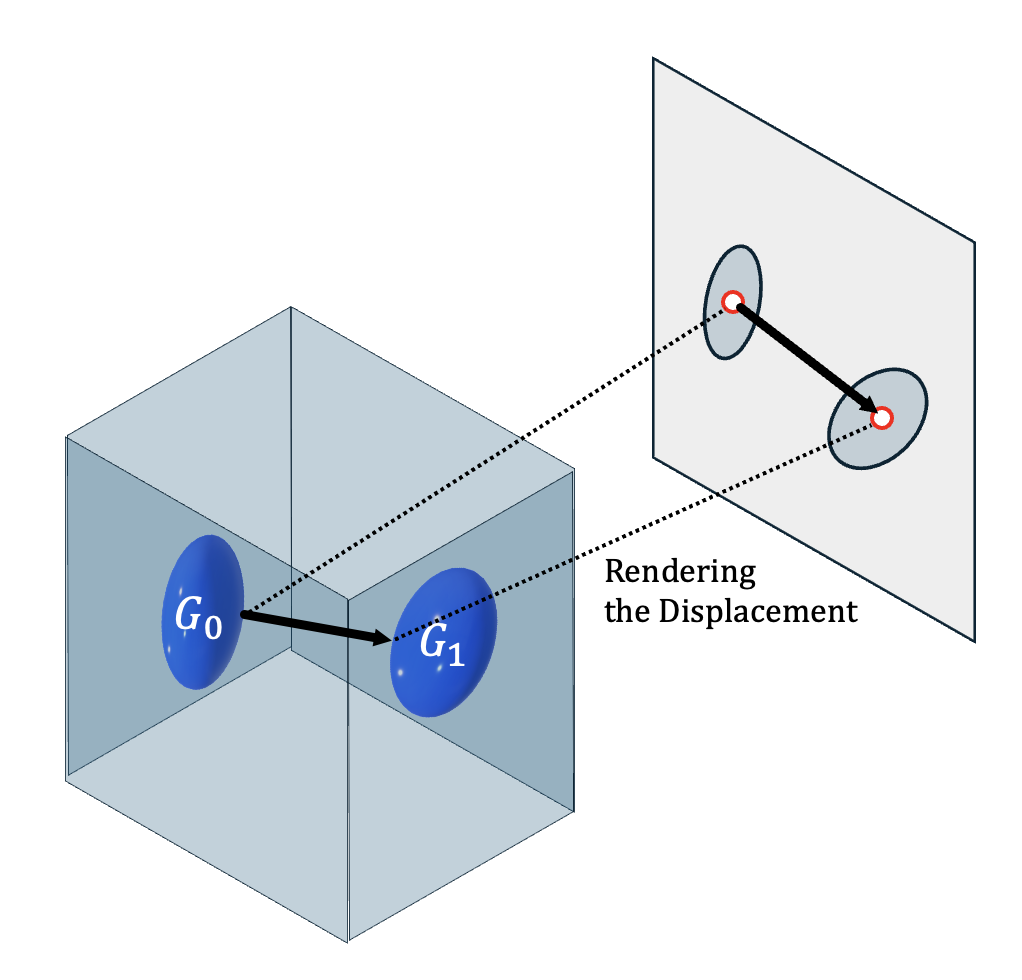 Projecting Gaussian motion to image-plane flow for zero-shot tracking.
Projecting Gaussian motion to image-plane flow for zero-shot tracking.
Zero-shot tracking recipe (details)
Render Gaussian motion as dense flow, then advect points.
- Predict Gaussian motion per frame.
- Project Gaussians to image-plane flow.
- Advect query points with the flow.
- Use anchor Gaussians when occluded (optional).
Projected centers: \(x_i^{(t)} = \Pi(\mu_i^{(t)})\)
Displacement: \(\Delta x_i^{(t)} = x_i^{(t+1)} - x_i^{(t)}\)
Flow: \(F^{(t)}(u) = \sum_i \alpha_i^{(t)}(u)\,\Delta x_i^{(t)}\)
Update: \(p^{(t+1)} = p^{(t)} + F^{(t)}(p^{(t)})\)
Occlusion-aware variant
Keep a fixed top‑k anchor set from the first frame, track their visibility, and mix flow with anchor proposals when visible mass is low.
Anchor mass: \(\omega^{(t)} = \sum_{i\in\mathcal{S}} \alpha_i^{(t)}(p^{(t)})\)
Weights over anchors: \(\tilde{\pi}_i^{(t)} = \dfrac{\alpha_i^{(t)}(p^{(t)})}{\sum_{j\in\mathcal{S}} \alpha_j^{(t)}(p^{(t)}) + \varepsilon}\)
Anchor proposal: \(\hat{p}_{\text{anch}}^{(t+1)} = \sum_{i\in\mathcal{S}} \tilde{\pi}_i^{(t)} \left(x_i^{(t)} + \Delta x_i^{(t+1)}\right)\)
Blend with flow if visible: \(p^{(t+1)} = (1-\beta)\big(p^{(t)} + F^{(t)}(p^{(t)})\big) + \beta\,\hat{p}_{\text{anch}}^{(t+1)}\)
Otherwise use anchors only: \(p^{(t+1)} = \hat{p}_{\text{anch}}^{(t+1)}\)
Hyperparams (from paper): k = 8, \(\tau_{\text{vis}} = 0.5\), \(\beta = 0.3\).
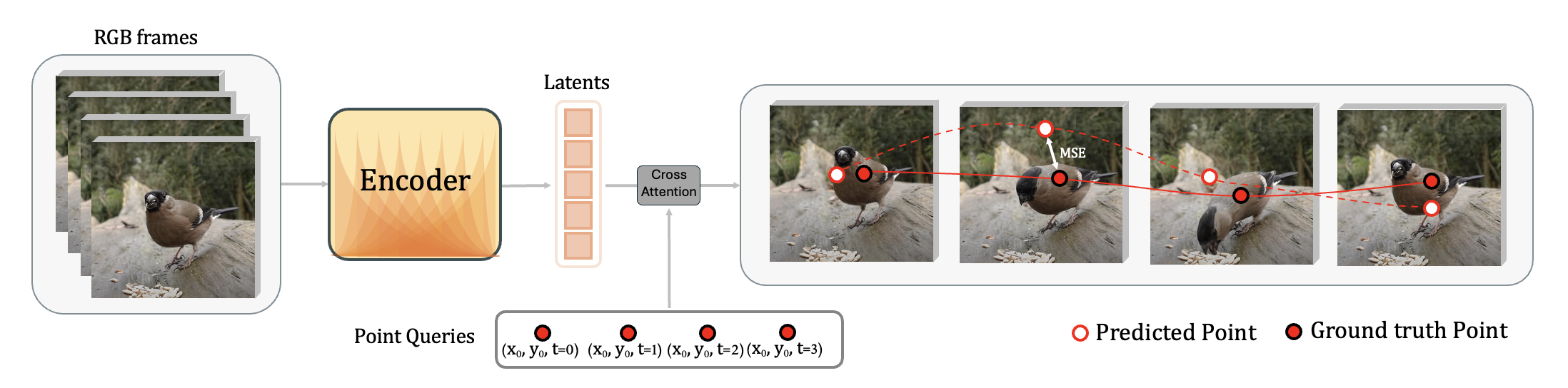 Fine-tuning: cross-attention readout over encoder latents improves precision and occlusion handling.
Fine-tuning: cross-attention readout over encoder latents improves precision and occlusion handling.
Pretraining
High masking ratio; decoder predicts Gaussians for frame 1 plus per-frame deltas; splatting closes the loop.
Zero-shot tracking
Project Gaussian motion to a flow field and advect points—no tracking labels.
Fine-tuning
Cross-attention readout over encoder latents sharpens localization and occlusion handling.
Results
From zero-shot tracking to fine-tuned precision; videos are the primary evidence.
Zero-shot
Stable tracks emerge from Gaussian motion without labels.
Jump to zero-shot
Comparisons
Video-GMAE vs. GMRW‑C: stability vs. tiny-detail fidelity.
See comparisons
Fine-tuned
Light supervision sharpens trajectories and occlusion handling.
View fine-tuned
Reconstructions
Pretraining renders show what the Gaussians capture.
Watch recon
Zero-shot Tracking
Correspondence emerges directly from Gaussian motion—no tracking labels.
What to look for:
- DAVIS: deforming objects and occlusions.
- Kinetics: diverse human actions and interactions.
- Failure modes: camera motion + high-frequency backgrounds + 256-Gaussian budget.
Comparisons vs. GMRW‑C
Video-GMAE is more temporally stable; GMRW‑C can better preserve tiny, fast details.
What to look for:
- Stability vs. early occlusion/dropouts.
- Tiny fast parts where GMRW‑C may track tighter.
TAP-Vid Kinetics comparison.
TAP-Vid DAVIS comparison.
Fine-tuned Tracking
Light supervision sharpens localization and occlusion handling.
What to look for:
- Reduced drift/jitter vs. zero-shot.
- More reliable occlusion handling.
Fine-tuned: TAP-Vid DAVIS (two sequences, looped).
Fine-tuned: TAP-Vid Kinetics (two sequences, looped).
Pretraining Reconstructions
Rendered Gaussian trajectories during pretraining capture coarse structure and motion.
What to look for:
- Coarse geometry and motion with few Gaussians.
- Fine detail limited by the 256-Gaussian budget.
Dynamic reconstructions from Gaussians.
Dynamic reconstructions from Gaussians.
Dynamic reconstructions from Gaussians.
Quantitative Results
Bars below show Video-GMAE zero-shot gains over GMRW on Kinetics and Kubric.
BibTeX
Cite this work as arXiv:2512.22489.
Copy-ready BibTeX
@misc{baranwal2025tracking3d,
title = {Tracking by Predicting 3-D Gaussians Over Time},
author = {Tanish Baranwal and Himanshu Gaurav Singh and Jathushan Rajasegaran and Jitendra Malik},
year = {2025},
eprint = {2512.22489},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
doi = {10.48550/arXiv.2512.22489},
url = {https://arxiv.org/abs/2512.22489}
}